1. 동적페이지와 정적페이지
| 동적페이지 (메모지) - 필요시 해당 페이지에 메모를 붙임. | 정적페이지 (종이책) - 항상 같은 페이지. |
| 웹 브라우저에 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지 - JSON(요리의 재료) : 클라이언트와 서버 간의 데이터 전송을 위해 사용 (데이터만 전송하여 클라이언트에 화면을 업데이트) |
웹 브라우저에 화면이 뜨면 이벤트에 의한 화면 변경이 없는 페이지 - HTML(요리의 완성된 모양) : 웹페이지의 내용이 담긴 코드 (구조, 텍스트, 이미지 등을 담고 있음) |

2. Crawling Naver Stock Datas (네이버 증권 사이트 주가 데이터 수집
더보기
- 수집할 데이터 : 일별 kospi, kosdaq 주가, 일별 환율(exchange rate) 데이터
- 데이터 수집 절차
- 웹서비스 분석 : url
- 서버에 데이터 요청 : request(url) > response : json(str)
- 서버에서 받은 데이터 파싱(데이터 형태를 변경) : json(str) > list, dict > DataFrame
import requests
import pandas as pd
1) 웹서비스 분석: url
- pc 웹페이지가 복잡하면 mobile 웹페이지에서 수집
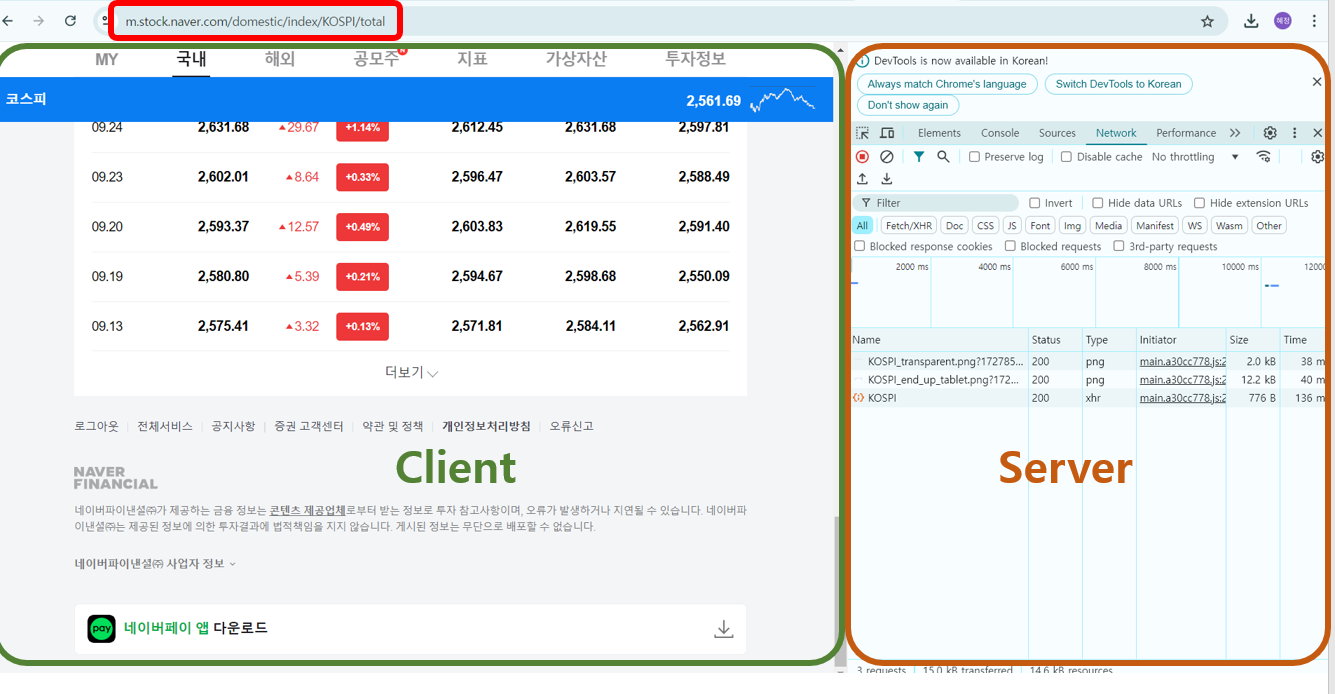
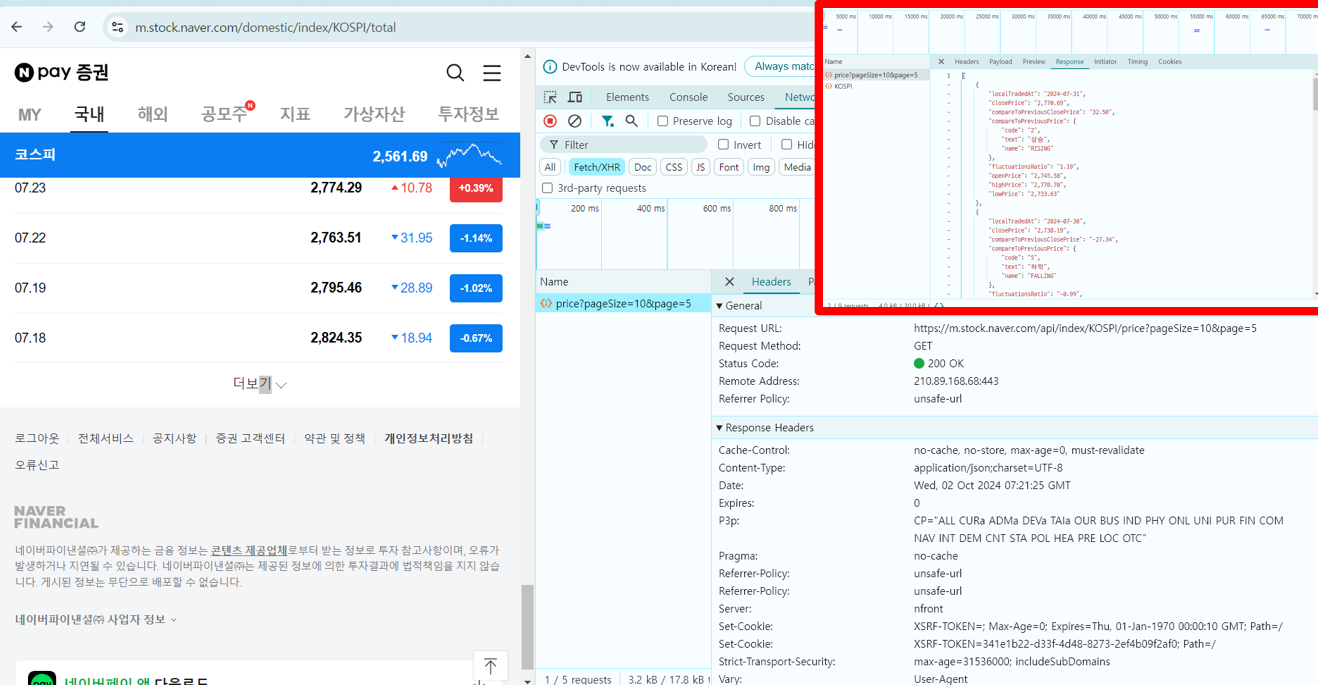
url = 'https://m.stock.naver.com/api/index/KOSPI/price?pageSize=10&page=2'
2) 서버에 데이터 요청 : request(url) > response : json(str)
- status의 코드를 확인
response = requests.get(url)
response
# <Response [200]>
3) 서버에서 받은 데이터 파싱 (데이터 형태를 변경)
data = response.json()
data[:2] # 리스트 내 하나의 딕셔너리는 row 값, 왼쪽 이름은 columns 명
df = pd.DataFrame(data)[['localTradedAt', 'closePrice']]
df.tail(2)
4) 함수로 만들기
def stock(code='KOSPI', page_size=10, page=1):
# 1. URL
if page_size > 60:
return 'pagesize less then 60!'
url = f'https://m.stock.naver.com/api/index/{code}/price?pageSize={page_size}&page={page}'
# 2. request(URL) > response(JSON(str))
response = requests.get(url)
# 3. JSON(str) > list, dict > DataFrame
return pd.DataFrame(response.json())[['localTradedAt', 'closePrice']]
'파이썬 > 데이터 수집' 카테고리의 다른 글
| [241002] 데이터 수집 - Python (Class) (3) | 2024.10.02 |
|---|---|
| [241002] 데이터 수집 #1 Web (2) | 2024.10.02 |

