* 어떻게 평가할 것인가?
| * 분류 모델 평가 | - 0인지 1인지를 예측하는 것 - 실제 값도 0과 1이고, 예측 값도 0과 1임 - 하지만 0을 1로 예측하거나 1을 0으로 예측할 수 있음 - 예측 값이 실제 값과 많이 같을 수록 좋은 모델이라 할 수 있음 - 정확히 예측한 비율로 모델 성능을 평가 => 정확도를 높여라!! |
| * 회귀 모델 평가 | - 회귀 모델이 정확한 값을 예측하기는 사실상 어려움 - 예측 값과 실제 값에 차이(=오차)가 존재할 것이라 예상함 - 예측 값이 실제 값에 가까울 수록 좋은 모델이라 할 수 있음 - 예측한 값과 실제 값의 차이(=오차)로 모델 성능을 평가 => 오차를 줄여라!! |
1. 회귀 모델 성능 평가
 |
- 우리가 실제로 예측하고 싶은 값, Target, 목푯값 - 이 값과 비교해 우리 모델의 성능을 평가할 것임 - 우리가 관심을 갖는 오차는 이 값과 예측값의 차이이다. |
 |
- 이미 알고 있는, 이미 존재하고 있는 평균으로 예측한 값 - 최소한 이 평균값 보다는 실젯값에 가까운 예측값을 원함 - 우리 모델의 예측값이 평균값보다 오차를 얼마나 더 줄였는지가 궁금하다. |
 |
- 우리 모델로 새롭게 예측한 값 - 이 예측값이 얼마나 정확한지 알고 싶은 상황 - 최소한, 아무리 못해도 평균값 보다는 좋아야 할 것임 - 우리 모델이 평균값보다 얼마나 잘 예측했을지 궁금하다. |
(2) 하나의 값
- 회귀모델의 성능은 실젯값과 예측값의 차이, 즉 오차의 크기로 평가한다.
- 그러므로 우선 우리 모델의 오차를 이야기 할 수 있어야 하는데,
| 실젯값 | 예측값 | 오차 (실젯값-예측값) | - 오차가 2, -1, 2, -3이라고 표현하기 보다는, 오차 평균으로 하나의 값으로 표현해야 대화가 쉽다. |
| 16 | 14 | 2 | |
| 15 | 16 | -1 | |
| 22 | 20 | 2 | |
| 25 | 28 | -3 |
① 오차 합 구하기
- 오차 평균을 구하기 위해서는 오차 합을 구해야 한다.
- 오차 제곱의 합과 오차 절대값의 합을 사용할 수 있다.

② 오차 제곱의 합
- 오차 제곱(SSE)의 합을 구한 후 평균을 구하는 방법 : MSE
- 오차 제곱이므로 루트를 사용해 일반적인 값으로 표현하는 방법 : RMSE

③ 오차 절대값의 합
- 오차 절대값의 합을 구한 후 평균을 구하는 방법 : MAE
- 오차 비율을 표시하고 싶은 경우 : MAPE

(3) 회귀 평가 지표 정리
| MSE | Mean Squred Error | 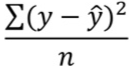 |
| RMSE | Root Mean Squred Error |  |
| MAE | Mean Absolute Error | 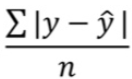 |
| MAPE | Mean Absolute Percentage Error |  |
=> 위 값이 모두 작을 수록 모델 성능이 좋은 것임.
(4) 오차를 바라보는 다양한 관점
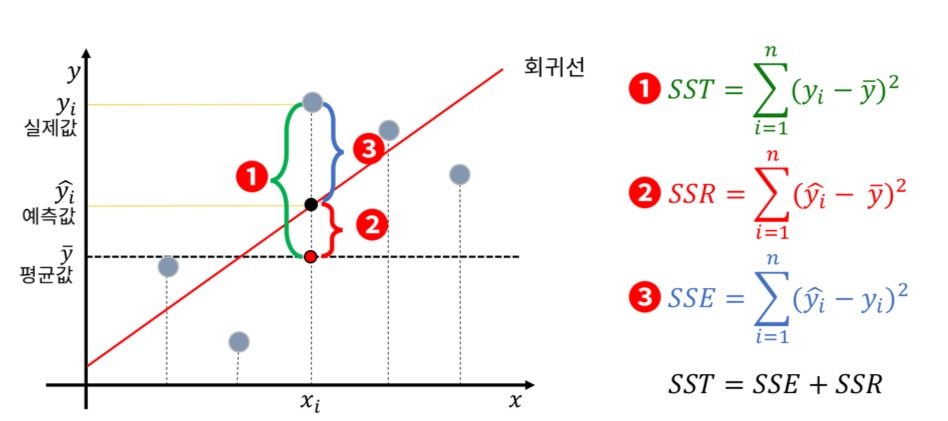
① SST : Sum Squared Total, 전체 오차 (최소한 평균보다는 성능이 좋아야 함, 우리에게 허용된 최소한의 오차)
② SSR : Sum Squared Regression, 전체 오차 중 회귀식이 잡아낸 오차
③ SSE = Sum Squared Error, 전체 오차 중에서 회귀식이 여전히 잡아내지 못한 오차
(5) 결정 계수 R2 (R-Squred)
- Coefficient of Determination
- MSE로 여전히 설명이 부족한 부분이 있다.
- 모델 성능을 잘 해석하기 위해서 만든 MSE의 표준화된 버전이 결정 계수이다.
- 전체 오차 중에서 회귀식이 잡아낸 오차 비율 (일반적으로 0~1 사이)
- 오차의 비 또는 설명력이라고도 부름
- R2 = 1이면 MSE = 0이고, 모델이 데이터를 완벽하게 학습한 것이다.
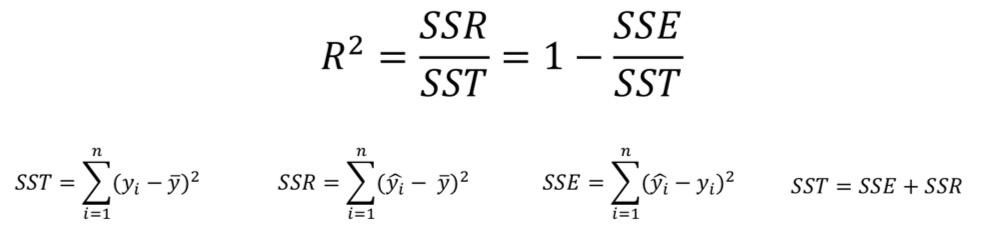
(6) 모델 평가하기
① 평가에 필요한 함수를 불러와 사용함
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_absolute_percentage_error
from sklearn.metrics import r2_score
② 실젯값(y_test)과 예측값(y_pred)를 매개변수로 전달해 평가함
# 평가하기
# mean_absolute_error(실젯값, 예측값)
print(mean_absolute_error(y_test, y_pred)
- MSE, RMSE, MAE, MAPE는 오류(Error)이므로 작을수록 좋고,
- R2 Score는 클수록 좋다.
2. 분류 모델 성능 평가
(1) 얼마나 정확하게 예측하였는가에 대한 평가
| 예측값 | |||
| 실젯값 | 0 | 1 | |
| 0 | 3 | 1 | |
| 1 | 2 | 4 | |
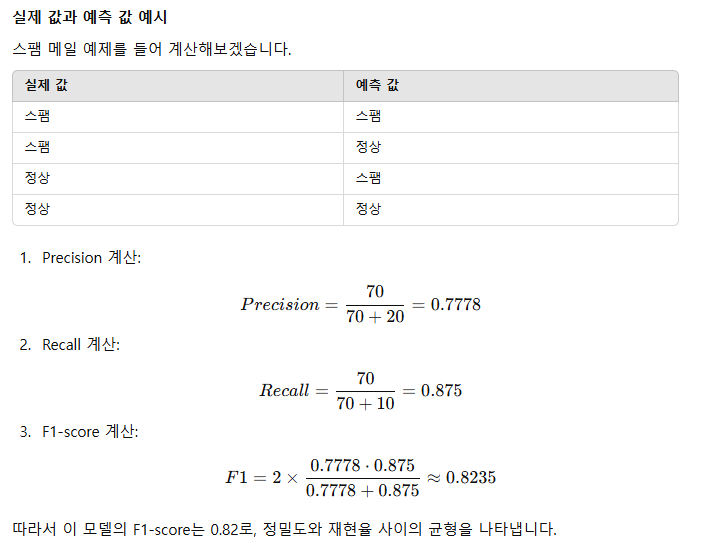
① 정확도 (Accuaracy) : 1과 0을 정확히 예측한 비율 = 7/10
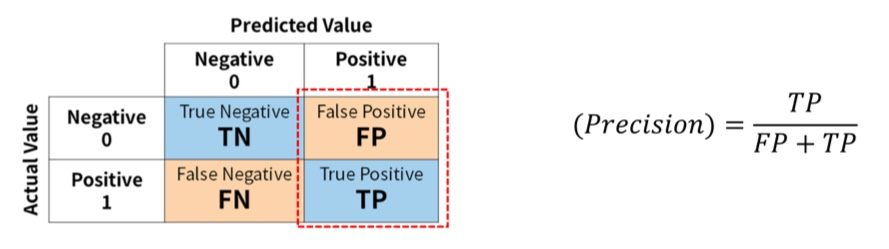
② 정밀도 (Precision) : 1이라 예측한 것 중에 정말 1인 비율 = 4/5
③ 재현율 (Recall) : 실제 1인 것을 1이라고 예측한 비율 = 4/6
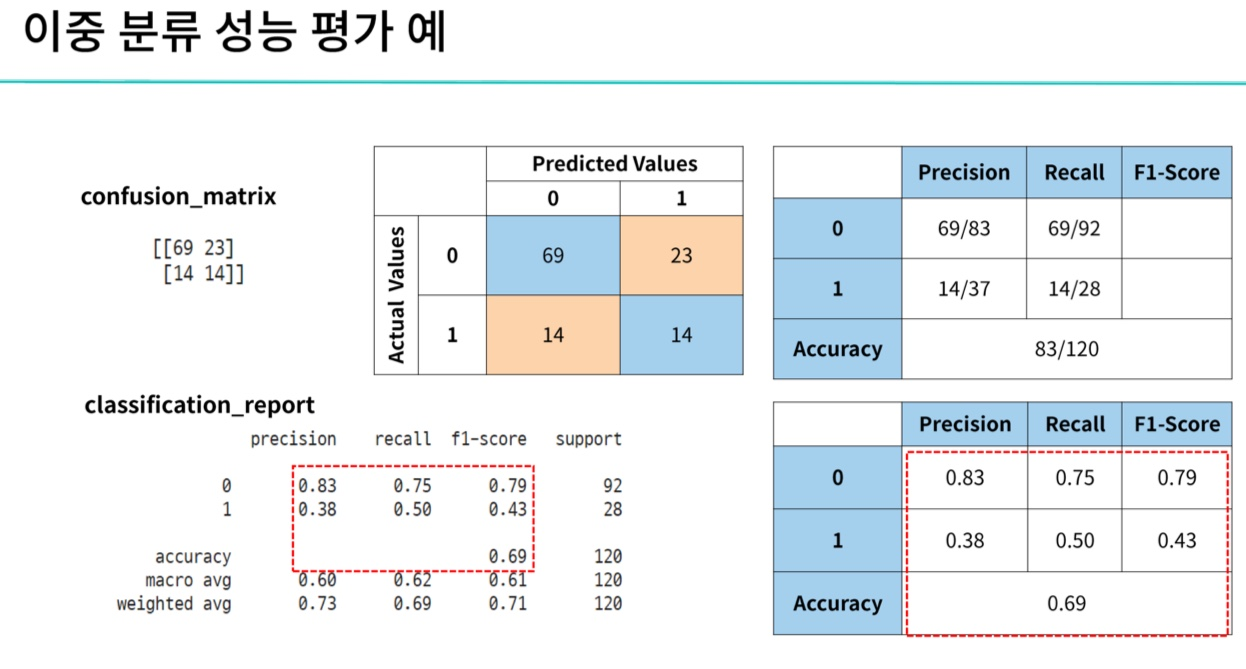
(2) 혼동 행렬
- Confusion Matrics (오분류표)
| Predicted Value | |||
| Actual Value |
Negative 0 |
Positive 1 |
|
| Negative 0 |
True Negative TN |
False Positive FP |
|
| Positive 1 |
False Negative FN |
True Positive TP |
|
* TN (True Negative, 진음성)
: 음성으로 잘 예측한 것 (음성을 음성으로 예측한 것)
* FP (False Positive, 위양성)
: 양성으로 잘 못 예측한 것 (음성을 양성으로 예측한 것)
* FN (False Negative, 위음성)
: 음성으로 잘 못 예측한 것 (양성을 음성으로 예측한 것)
* TP (True Positive, 진양성)
: 양성으로 잘 예측한 것 (양성을 양성이라고 예측한 것)
- 정밀도와 재현율은 기본적으로 Positive에 대해 이야기 함
- Negative에 대한 정밀도와 재현율도 의미를 가진다.
① Accuarcy (정확도)
- 정분류율이라고 부르기도 함
- 전체 중에서 Positive와 Negative로 정확히 예측한 (TN + TP) 비율
- Negative를 Negative로 예측한 경우도 옳은 예측임을 고려하는 평가지표
- 가장 직관적으로 모델 성능을 확인할 수 있는 지표이다.

② Precision(정밀도)
- 예측관점
- Positive로 예측한 것 중에서 실제 Positive인 비율
- ex) 비가 내릴 것으로 예측한 날 중 실제 비가 내린 날의 비율
- ex) 암이라 예측한 환자 중 실제 암인 환자의 비율
③ Recall (재현율,민감도)
- 실제 관점
- 실제 Positive 중 Positive로 예측한 비율
- ex) 실제 비가 내린 날 중 비가 내릴 것으로 예측한 날의 비율
- ex) 실제 암인 환자 중에서 암이라고 예측한 환자의 비율
=> 재현율이 낮을 경우 발생하는 문제의 심각성이 예측율이 낮을 경우 발생하는 문제의 심각성보다 큼
- 암이 아닌데, 암이라고 예측한 경우는 불필요한 비용이 발생하게 되지만,
- 암인데 암이 아니라고 하였으니 심각한 결과를 초래할 수 있다.

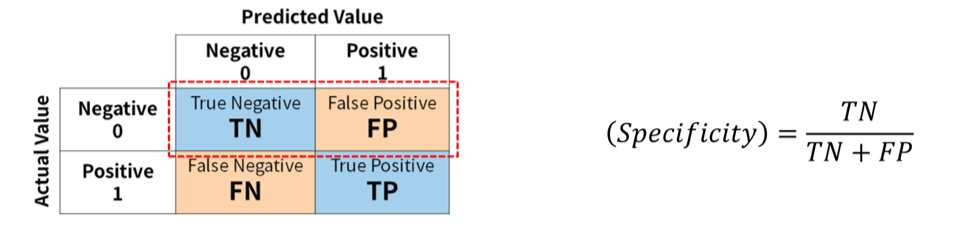
④ Specificity(특이도)
- 실제 Negative 중에서 Negative로 예측한 비율
- ex) 실제 비가 내리지 않은 날 중 비가 내리지 않을 것으로 예측한 날의 비율
- ex) 실제 암이 아닌 환자 중에서 암이 아니라고 예측한 환자의 비율
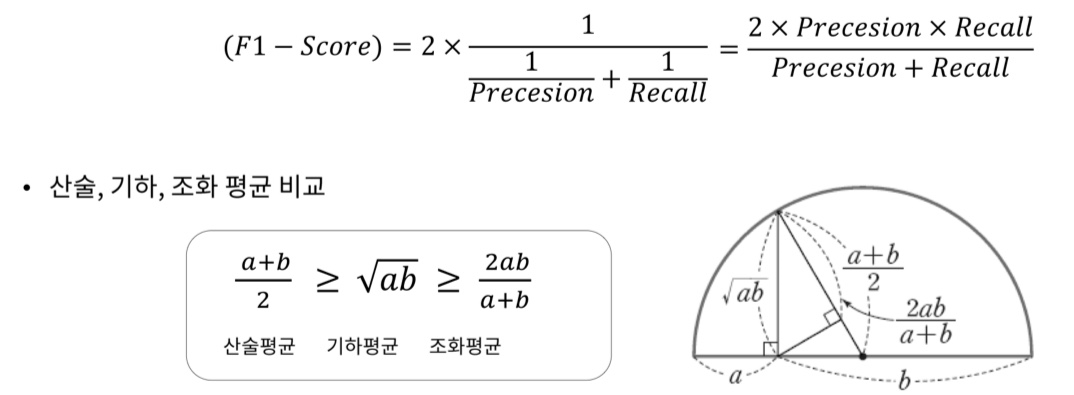
⑤ F1-score
- 정밀도와 재현율의 조화 평균
- 분자가 같지만 분모가 다를 경우, 즉 관점이 다른 경우 조화 평균이 큰 의미를 가진다.
- 정밀도와 재현율이 적절하게 요구 될 때 사용한다.
- 즉 정밀도와 재현율의 균형을 나타냄
 |
 |
(3) 모델 평가하기
# 함수 불러오기
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
# 평가하기
# accuracy_score
print(accuracy_score(y_test, y_pred))
print(precision_score(y_test, y_pred, average=None))
# 다중 분류일 때 average=None
# 정밀도와 재현율 등은 average 매개변수로 평균을 사용할지 개별 값으로 표시할 지 지정
# classification_report 함수를 사용해 한 번에 여러 평가지표를 확인할 수 있음
'머신러닝 > 지도학습' 카테고리의 다른 글
| [머신러닝-지도] 머신러닝 소개 (2) | 2024.12.15 |
|---|
