1. 최종 모델 저장하기
# 딥러닝 모델의 메소드로 .save가 제공됨.
model1.save('dyong.keras')
# 모델 로딩하기
# 모델 로딩하는 함수는 별도로 불러와야 함(load_model)
from keras.models import load_model
model2 = load_model('dyong.keras')
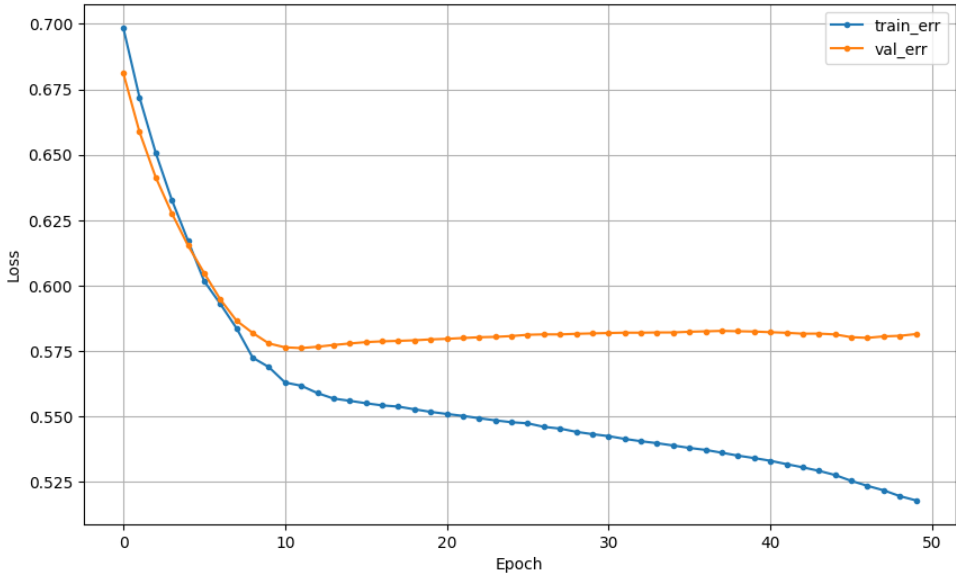
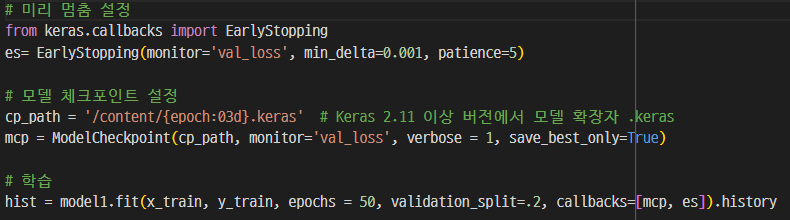
2. 중간 체크포인트 저장하기
cp_path = '/content/{epochs:03d}.keras'
mcp = ModelCheckpoint(cp_path, monitor='val_loss', verbose=1, save_best_only)=True)
# 학습
hist = model.fit(x_train, y_train, epochs=50, validation_split=.2, callback=[mcp]).history
 |
 |
| 12까지 저장 |
## 참고1_ 폴더정리 : 위에서 저장한 파일들 제거하기
import os
def delete_keras_files(directory):
for filename in os.listdir(directory):
if filename.endswith(".keras"):
file_path = os.path.join(directory, filename)
try:
os.remove(file_path)
print(f"Deleted: {file_path}")
except Exception as e:
print(f"Error deleting {file_path}: {e}")
# 삭제할 디렉토리 지정
directory_to_delete_from = "/content/"
# 확장자가 .keras인 파일 삭제
delete_keras_files(directory_to_delete_from)
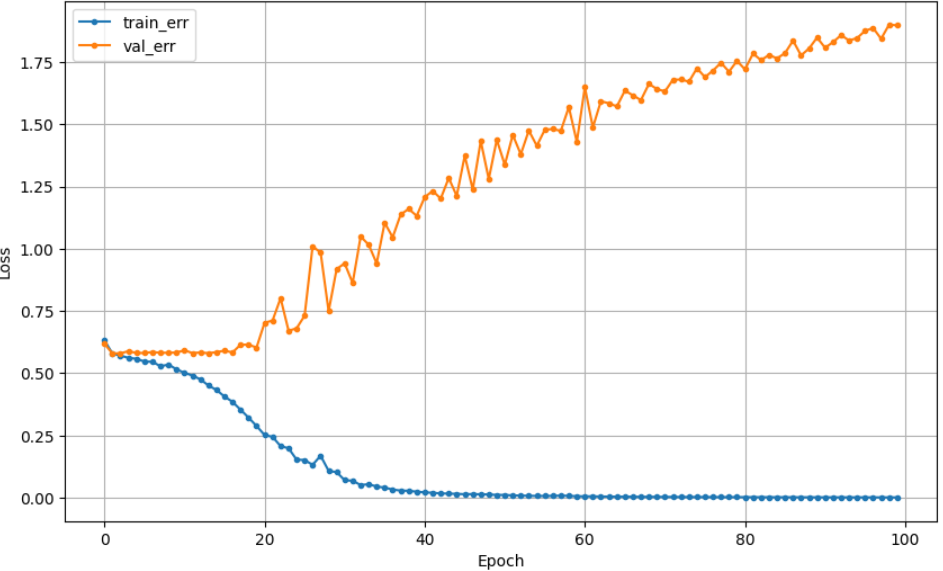
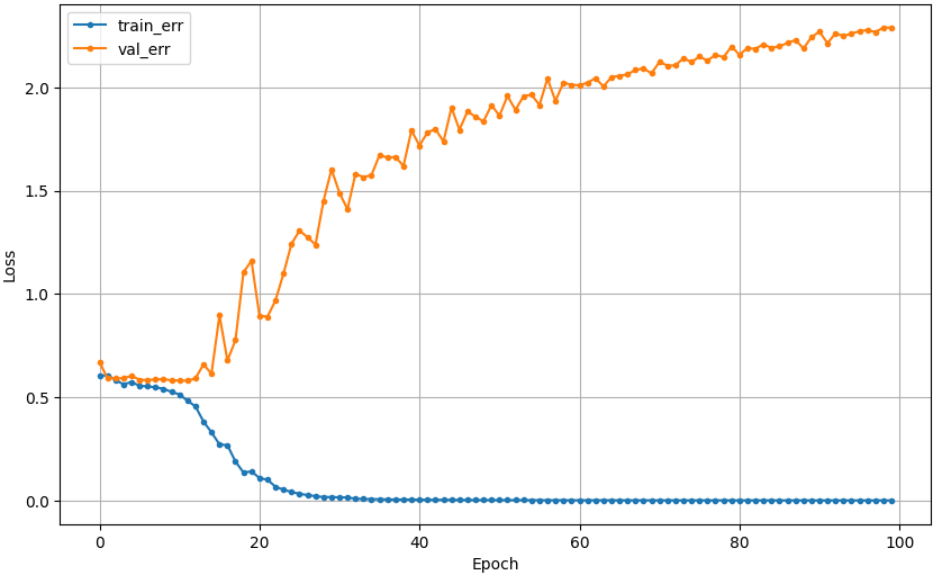
## 참고2_ activation : 활성함수 (relu, swish)
일반적으로 relu를 쓰고 새로 나온 활성화 함수가 swish임.
=> 강사님은 큰 차이 없으니, relu를 쓰라고 하셨는데, swish가 결과가 더 좋게 나오긴 했음.
(이건 개인 선택의 몫)
| relu | swish |
 |
 |
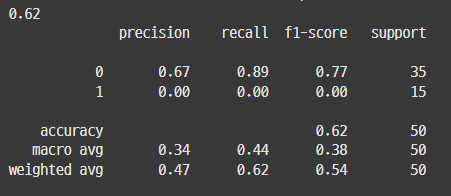 |
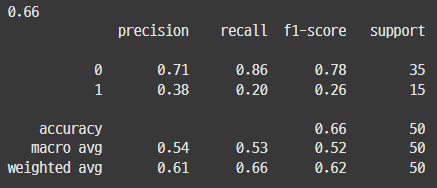 |
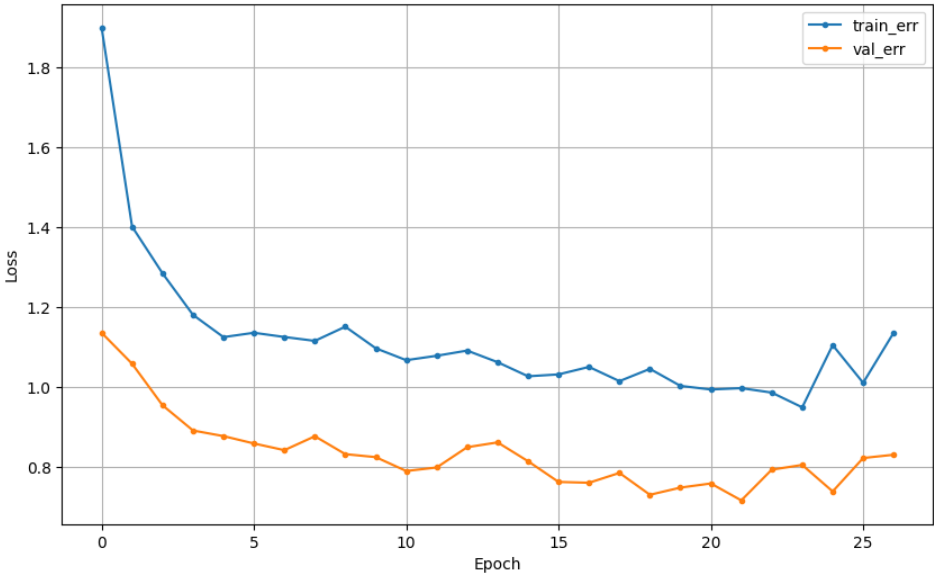
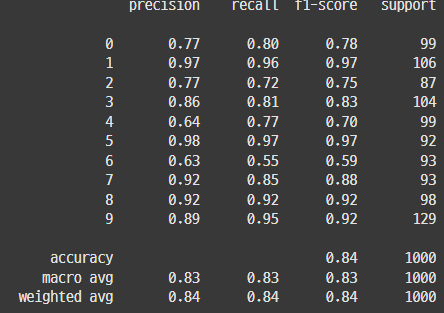
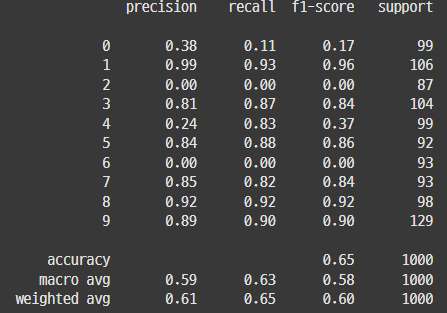
## 참고3_ early stopping과 dropout 함께 쓰기
| Early Stopping | DropOut | Early Stopping + DropOut |
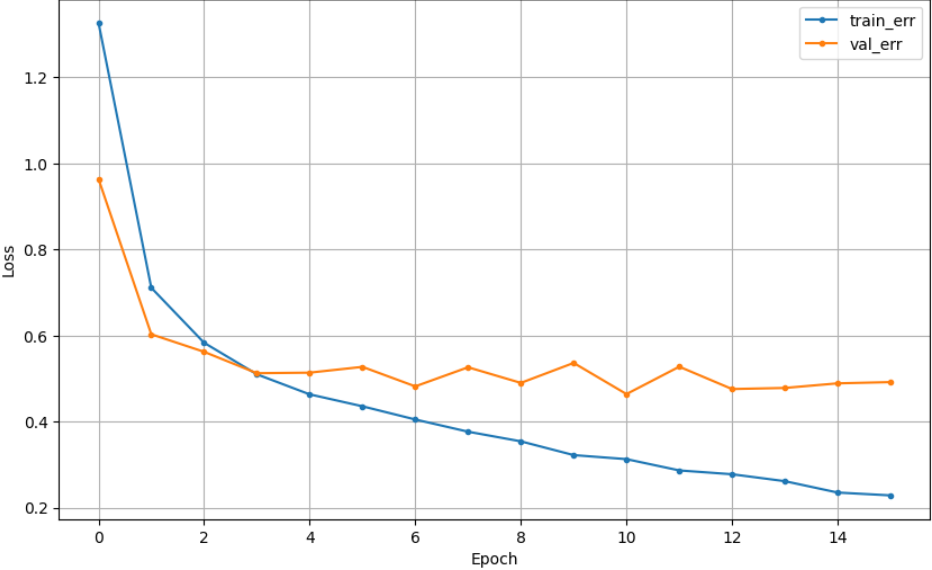 |
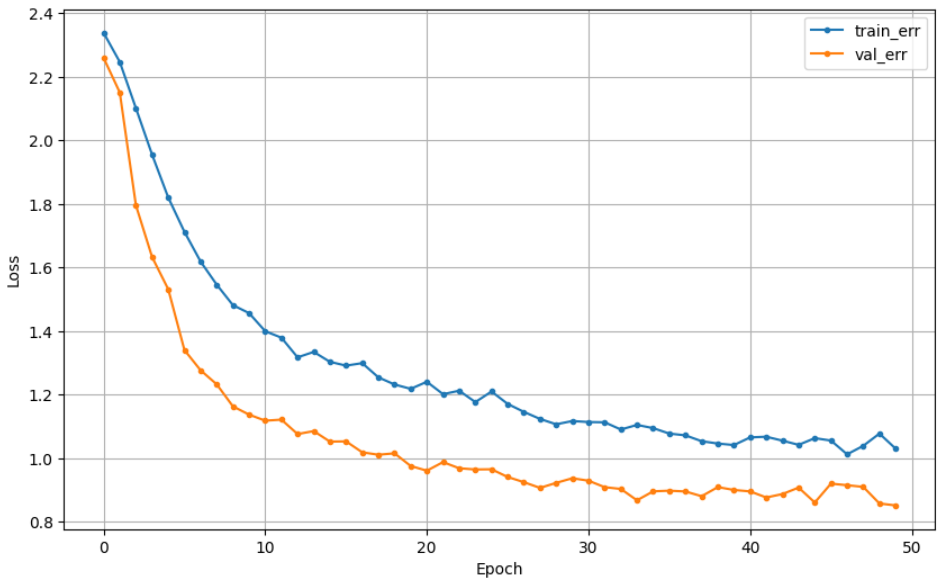 |
 |
 |
 |
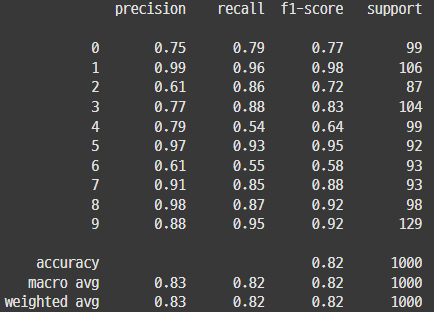 |
=> 같이 쓰면 성능이 더 향상될 수 있다고 하는데, EarlyStopping 쓴게 가장 좋네(왜일까?)
더보기
** 챗지피티의 답변
Dropout과 Early Stopping의 효과는 모델의 구조, 데이터 특성, 그리고 학습 환경에 따라 다르게 나타날 수 있습니다. 두 기법을 함께 사용했을 때 성능이 떨어지는 경우는 몇 가지 요인에 의해 발생할 수 있습니다:
- 모델의 복잡도와 드롭아웃 비율:
- 드롭아웃 비율이 너무 높으면 모델이 충분히 학습하지 못할 수 있습니다. 특히 작은 모델이나 데이터가 복잡하지 않은 경우, 드롭아웃으로 뉴런을 많이 비활성화하면 오히려 필요한 정보를 충분히 학습하지 못해 성능이 저하될 수 있습니다.
- 드롭아웃이 적용된 모델이 학습하는 동안 뉴런의 일부가 무작위로 꺼지기 때문에, 모델이 안정적으로 수렴하는 데 시간이 더 걸릴 수 있습니다. 이 경우 Early Stopping이 너무 일찍 작동하면 과소적합이 발생할 수 있습니다.
- 데이터 크기와 특성:
- 데이터셋이 작거나 모델이 상대적으로 간단한 문제를 다루는 경우, 드롭아웃과 Early Stopping을 동시에 적용하면 학습이 과도하게 억제되어 성능이 떨어질 수 있습니다.
- 복잡한 모델에서는 두 가지를 함께 사용하는 것이 효과적일 수 있지만, 단순한 모델이나 데이터에서는 드롭아웃이 오히려 학습을 방해할 수 있습니다.
- Early Stopping의 모니터링 설정:
- Early Stopping의 patience(모니터링할 에포크 수)나 min_delta(최소 성능 변화폭) 등 파라미터가 너무 작으면, 학습이 안정화되기 전에 멈추는 일이 발생할 수 있습니다. 드롭아웃을 적용하면 학습이 안정적으로 수렴하는 데 시간이 더 걸리므로, Early Stopping의 patience를 조금 늘리는 것이 도움이 될 수 있습니다.
- 모델 종류와 드롭아웃의 적합성:
- 드롭아웃은 일반적으로 합성곱 신경망(CNN)이나 순환 신경망(RNN)보다는 완전 연결층에 주로 사용됩니다. CNN의 경우에는 배치 정규화(batch normalization)가 드롭아웃보다 더 효과적일 수 있습니다.
따라서, 성능이 떨어진다면 다음을 시도해 볼 수 있습니다:
- 드롭아웃 비율을 낮추거나 제거해보세요. 간단한 문제나 작은 모델에서는 드롭아웃이 불필요할 수 있습니다.
- Early Stopping의 patience 값을 늘려서 학습을 충분히 시도해 보세요.
- 모델의 구조와 데이터에 따라 드롭아웃 또는 Early Stopping 중 하나만 사용하는 방법도 고려할 수 있습니다.
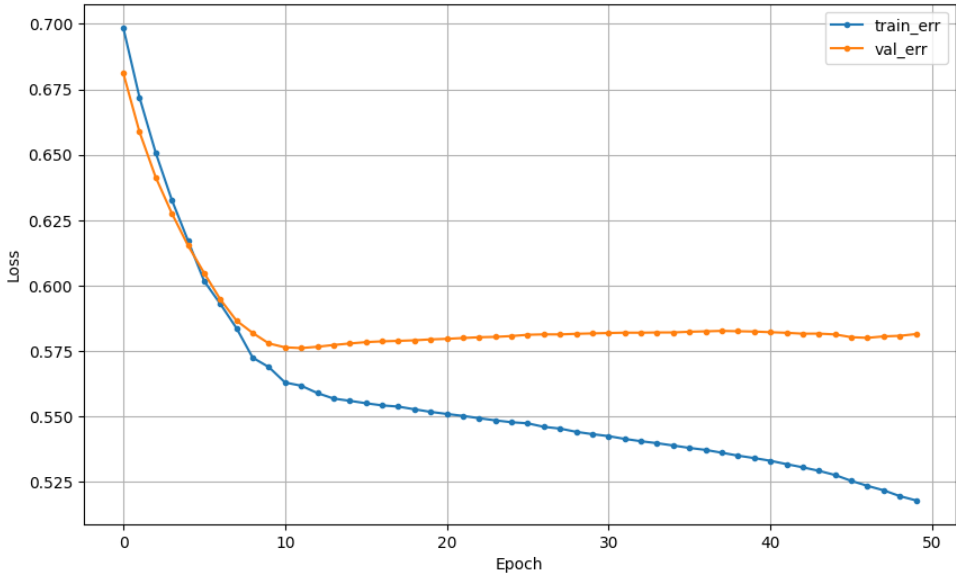
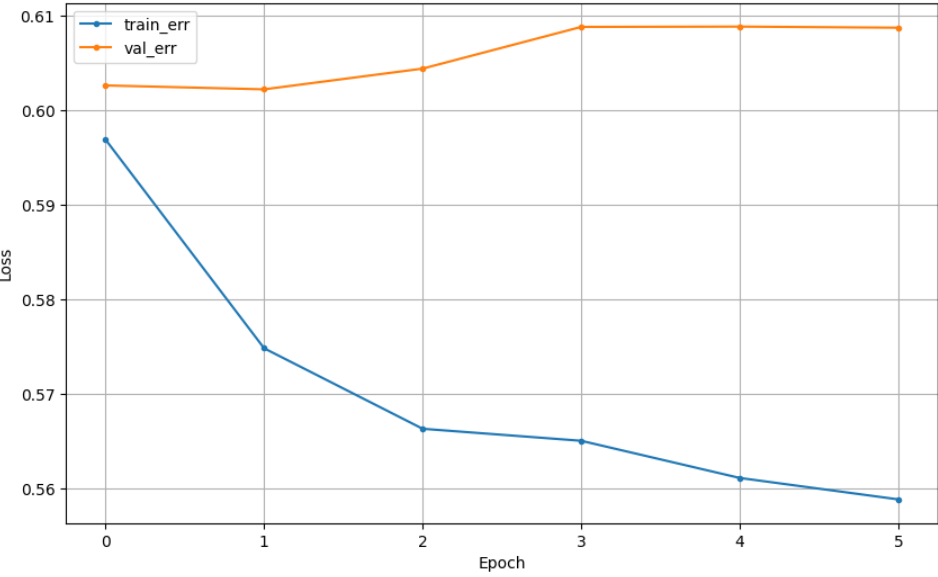
## 참고4_ ModelCheckpoint + Early Stopping
| ModelCheckpoint 012까지 저장 |
ModelCheckpoint + early stopping 002까지 저장 |
 |
 |
 |
 |
'딥러닝' 카테고리의 다른 글
| [딥러닝] 언어모델 이해 (1) ChatGPT API로 연결하기 _ 20241105 (8) | 2024.11.05 |
|---|---|
| [딥러닝] CNN _ 20241104 (0) | 2024.11.04 |
| [딥러닝] 딥러닝 성능관리 _ 20241101 (2) | 2024.11.01 |
| [딥러닝] 딥러닝 모델링 (#2. 이진분류, 다중분류) _ 20241031 (4) | 2024.10.31 |
| [딥러닝] 딥러닝 모델링 (#1. Regression) _ 20241031 (3) | 2024.10.31 |



