* 실습 내용
# 5. 부하 분산 및 자동 조정
- Application Load Balancer 생성
- 시작 템플릿 구성
- Auto Scaling 그룹 생성
- 작동 테스트
* 클라우드 서비스 수요 예측의 어려움
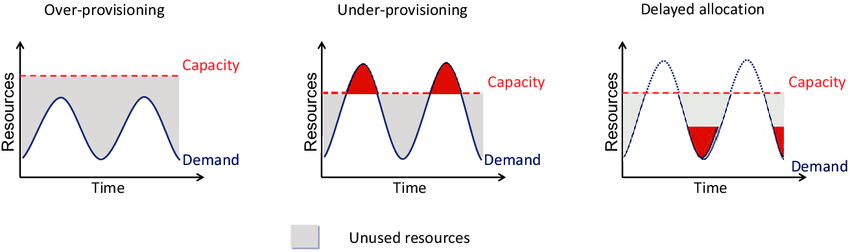
- Over-provisioning : 불필요한 리소스(비용) 낭비
- Under0provisioning : 고객 신뢰도, 만족도 혹은 매출 저하
- Delayed allocation : 수요 변화에 따른 신속한 대응이 어려움
* 탄력성 확보
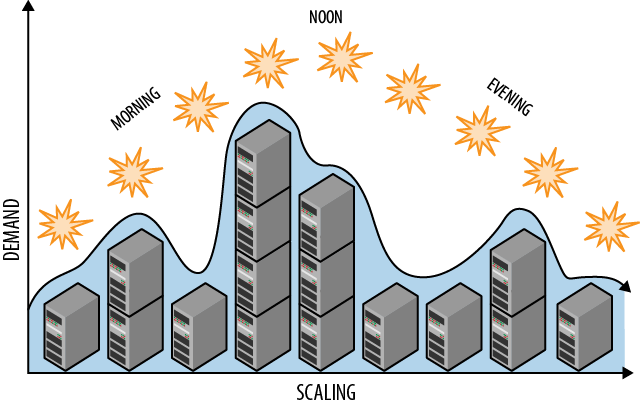
- 수요에 따른 용량 요구사항 변화를 즉시 반영하기 위해 자동으로 컴퓨팅 리소스(ex.인스턴스 개수)를 확장 및 축소하여 대응할 수 있는 탄력성 확보가 반드시 필요하다.
1. Amazon EC2 Auto Scaling
- 애플리케이션이 변화하는 트래픽 요구를 처리할 수 있는 적정 용량을 갖추도록 지원한다. (가용성 향상)
- 여러 개의 가용 영역을 사용하도록 Auto Scaling을 구성할 경우, 하나의 가용 영역이 사용 불가 상태가 되면 다른 가용 영역에서 새 인스턴스를 시작하여 이에 대처할 수 있다. (내결함성 향상)
- 수요 변화에 따라 용량을 동적으로 조정하므로 사용한 EC2 인스턴스에 대해서만 비용을 지불할 수 있다. (비용 최적화)
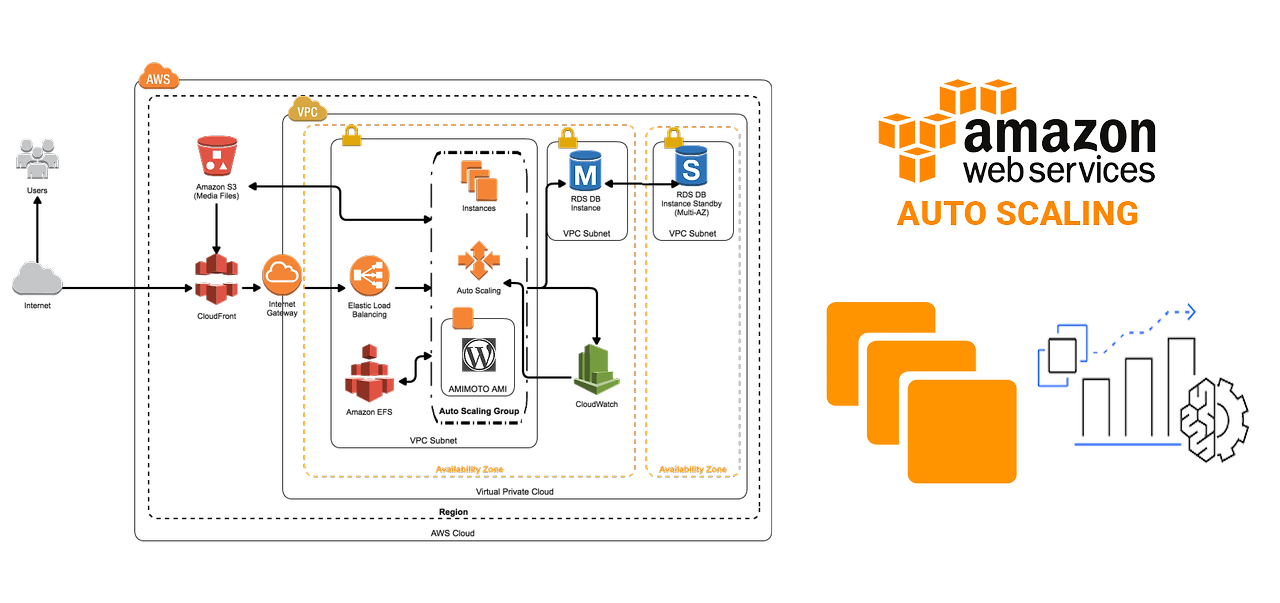
(1) Auto Scaling 구성요소
| 시작 템플릿 | - 그룹에서 생성할 인스턴스 구성 정보를 지정하기 위해 활용 - AMI, 인스턴스 유형, 키 페어, 네트워크, 보안 그룹, 사용자 데이터, IAM Role, EBS 볼륨 매핑 등으 ㅣ정보를 지정할 수 있음 |
| ASG 그룹 | - 그룹을 생성할 때 EC 인스턴스의 최소 및 최대 인스턴스 수와 원하는 인스턴스 수를 지정 |
| 조정 정책 | - ex. 지정한 조건의 발생(동적 확장) 또는 일정에 따라 조정하도록 그룹을 구성할 수 있음. |
① 시작 템플릿
- 자동 확장 과정에서 동일한 구성의 가상머신을 생성하기 위해 인스턴스 구성 정보를 사전 정의하여 템플릿화
- 인스턴스 이미지, 인스턴스 유형, 네트워크 정보, 스토리지(블록 디바이스 매핑), 사용자 데이터(쉘 스크립트), 보안그룹, I AM Role 등
② Auto scaling 그룹
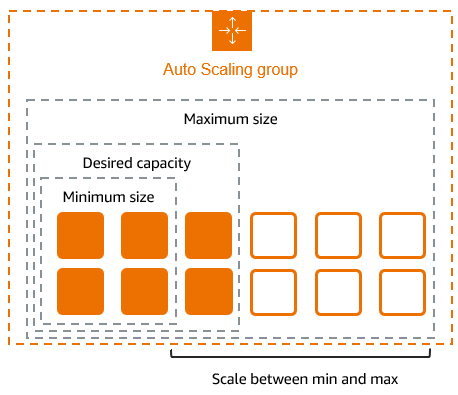
- Auto scaling 그룹의 크기는 서비스 특성을 고려하여 사용자가 설정할 수 있다.
- 원하는 용량에 맞게 인스턴스 수를 유지하고 지정한 최대, 최소 개수 내에서 자동 확장과 축소를 진행한다.
- 조정 정책을 사용하여 그룹의 인스턴스 수를 동적으로 늘리거나 줄일 수 있다.
- 인스턴스에 대한 주기적인 상태 확인을 수행하여 비정상 상태가 되면 그룹에서는 비정산 인스턴스를 종료하고 이를 대체할 다른 인스턴스를 자동으로 시작한다.
③ 조정 정책
| Dynamic Scaling | Scheduled Scaling | Predictive Scaling |
| - 조건 변화에 따라 동적으로 조정이 필요할 경우에 유용 - ex.임계값을 초과한 경우 정해진 CPU 사용률을 유지하기 위한 조정 실행 |
- 예측 가능한 워크로드인 경우 일정(시간/날짜)에 따라 조정하고자 할 경우 - ex. 퇴근시간 후 개발 및 테스트 인스턴스 종료 |
- AI 기반의 조정 방식으로 규칙을 수동으로 조정할 필요가 없음 - ex. 트래픽 패턴을 분석하여 인스턴스 수를 사전에 늘리고 줄임 |
2. Elastic Load Balancer

- 수신되는 애플리케이션 트래픽을 여러 EC2 인스턴스, 컨테이너 등으로 분산하는 관리형 로드밸런싱 서비스
- 한 리전 내 단일 가용 영역 또는 여러 가용 영역에서 애플리케이션 트래픽에 대한 부하 분산을 처리
- 가용 영역 하나가 사용할 수 없는 상태가 되거나 정상 상태의 인스턴스를 가지고 있지 않은 경우 로드밸런서는 다른 가용 영역에 있는 정상 상태의 인스턴스로 트래픽을 라우팅
(1) ELB 아키텍처

- 용도에 따라 외부(인터넷 경계) 또는 내부 로드밸런스를 활용할 수 있다.
- 인터넷 경계 로드밸런서는 Public IP를 갖게 되며 DNS 와 연동되어 변환된다.
- VPC 내부 트래픽의 부하분산을 위한 내부 로드밸런서의 노드는 프라이빗 IP 주소만 가지며 내부 DNS와 연동된다.
- 인터넷 경계 및 내부 로드 밸런서는 모두 프라이빗 IP 주소를 사용하여 대상으로 요청을 라우팅하므로 대상이 퍼블릭 IP 주소 없이도 로드밸런서에서 요청을 수신할 수 있다.
(2) ELB 특징
- 초당 수백만 개의 요청을 로드밸런싱할 수 잇으며 고가용성 구성, 자동 확장/축소, 강력한 보안성을 갖추고 있다.
- HTTP, HTTPS, TCP, UDP 및 SSL(보안 TCP, UDP) 프로토콜을 사용한다.
- AWS 외부에서 유입되는 트래픽 혹은 내부 트래픽 부하분산을 위한 다양한 로드밸런서(L7/L4) 유형을 지원한다.
- 백엔드 인스턴스에 대한 상태 확인(Health Check)를 통해 실시간으로 애플리케이션 상태 및 성능을 모니터링하고 병목 현상을 파악한다.
① ELB 내부 작동방식
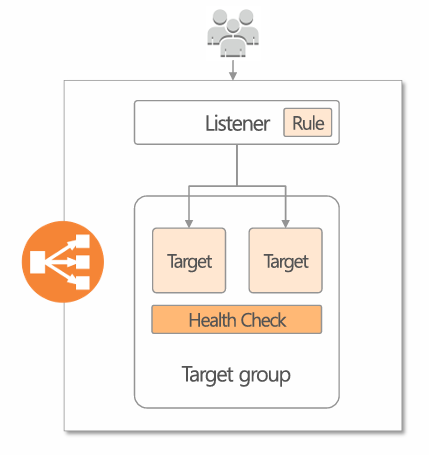 |
- 리스너는 로드밸런싱 규칙을 정의하는 구성요소 - 프로토콜과 포트를 기반으로 연결요청을 확인하고 정의한 규칙에 따라 등록된 대상 그룹(Target group)으로 요청을 라우팅 - 대상 그룹에 등록된 대상에 상태 확인(Health Check)을 수행하여 정상 상태로 판정된 경우에만 트래픽을 라우팅 |
② 상태 확인(Health Check)
- 주기적인 Health Check를 통해 대상이 정상 상태로 판정되어야 요청을 라우팅한다.
| 프로토콜 | 상태 확인을 위해 사용하는 프로토콜 | 포트 | 대상에서 상태 확인을 할 때 사용하는 포트 |
| 정상 임계값 (Healthy threshold) |
정상 간주를 위한 연속적인 상태확인 성공횟수 | 비정상 임계값 (Unhealthy threshold) |
비정상적으로 간주하기 위해 필요한 연속적인 상태확인 실패 횟수 |
| 제한시간(Timeout) | 대상으로부터 응답 대기 기간 | 간격(Interval) | 상태확인 간의 간격 |
| 성공코드(Success Codes) | 대상으로부터 성공응답을 체크하는 HTTP code |
③ 오프로딩
 |
- HTTPS를 통한 사용자 요청이 EC2 인스턴스로 직접 전달되게 되면 개별 EC2 인스턴스에서 TLS 암호화를 복호화하는데 많은 컴퓨팅 리소스가 필요하다. - 이를 해결하기 위해 Application Load Balancer에서 HTTPS 연결을 종료할 수 있는데, 이를 위해 SSL 인증서를 로드밸런서에 설치한다. - 로드밸런서는 이 인증서를 사용하여 SSL 연결을 종료한 후, 클라이언트의 요청을 복호화하여 HTTP 연결로 요청을 대상으로 전송한다. |
③ 고정 세션 (Sticky sessions)
- 동일한 클라이언트에서 들어오는 요청을 동일한 대상으로 라웉이하는 메커니즘(=Session affinity)
- 쿠키를 활용하여 사용자가 한번 접속한 적 있는 서버를 기억해두고 사용자가 다시 접속하더라도 기존 커넥션이 있었던 서버로 연결해주는 기능이다.
 |
- 사용자 요청에 EC2가 응답을 보낼때 ALB가 응답 헤더에 쿠키를 포함시켜 전달한다. - 이후 사용자가 재 요청시 해당 쿠키를 동봉하여 전달하면 ALB는 커넥션이 생성되었던 EC2에 연결한다. |
④ 등록취소 지연
 |
- Deregistration delay == Connection Draining - 인스턴스 등록 취소 시 인스턴스에 어느 정도의 시간을 주어 현재 진행중인 요청 처리를 완료할 수 있도록 하는 기능 - 인스턴스가 Draining 되면 ELB는 등록 취소 중인 인스턴스로는 새로운 요청을 보내지 않는다. - 등록 취소 프로세스를 완료하기 전에 300초(기본값) 동안 대기 - ex. 주문 취소, 구독 취소 등 |
(3) ELB 유형
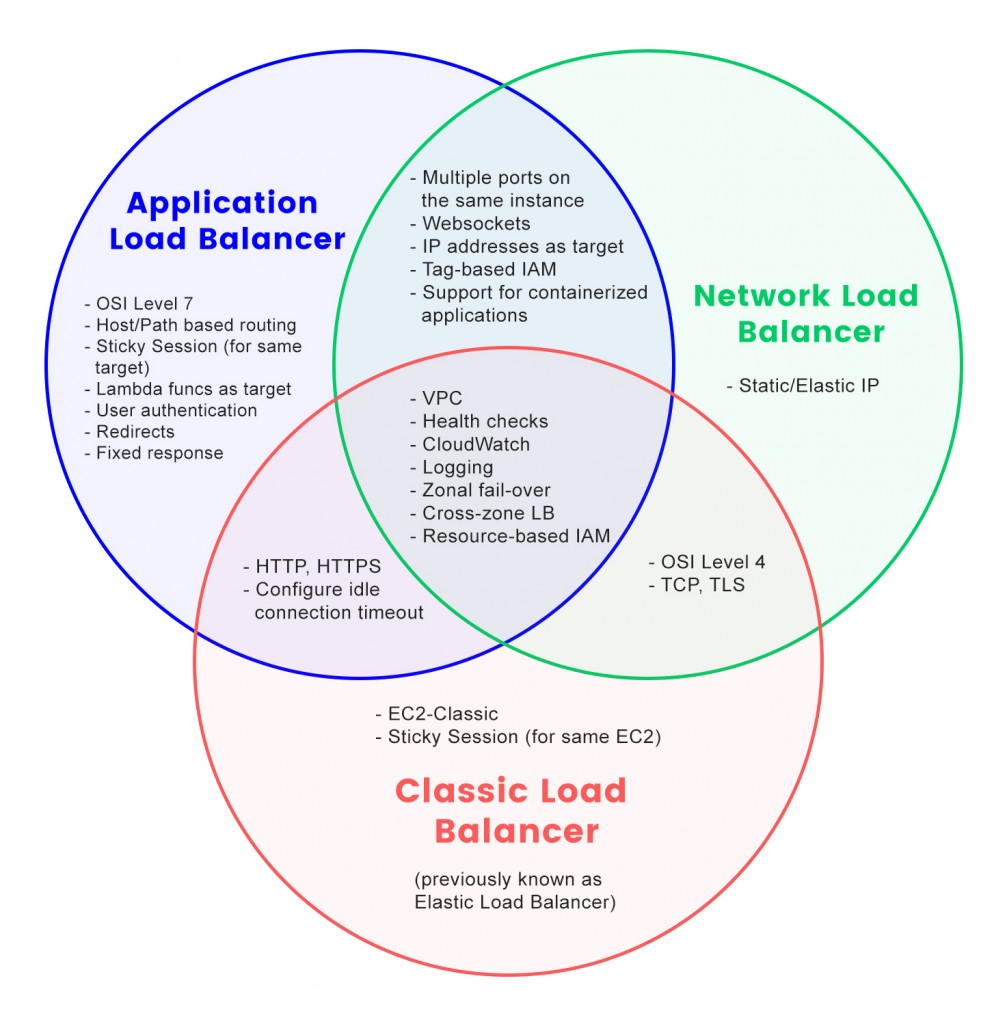
① Application Load Balancer
- HTTP, HTTPS 트래픽을 활용하는 애플리케이션을 위한 L7 계층 로드밸런서
- 컨텐츠 기반, 가중치 기반 로드밸런싱 등 고급 부하 분산 기능 지원
- 클라이언트가 IPv4 또는 IPv6을 통해 ALB에 연결할 수 있다.
- 고정 IP 설정이 불가, 보안 그룹 설정 지원은 가능하다.
* 컨텐츠 기반 라우팅
- ALB는 컨텐츠 기반 라우팅(Content-based Routing)을 지원
- 리스너에서 정의한 규칙에 따라 대상으로 요청을 라우팅하는 방법 결정
 |
- 요청 URL의 경로 패턴 기반 라우팅 (path-pattern, 경로 정보를 기반으로) - 호스트 이름 기반 라우팅(도메인 네임별) - HTTP 요청 메소드 기반 (http-requests-method, GET/POST/PUT/DELETE) - HTTP 헤더 기반 (헤더 내 정보 기반의 규칙) - 요청의 소스 IP 기반 라우팅 등 |
* 가중치 기반 라우팅
- ALB는 가중치 기반 라우팅 (Weighted Routing)을 지원
- 리스너 규칙의 전달 작업에 둘 이상의 대상 그룹을 추가하고 각 그룹에 가중치를 지정
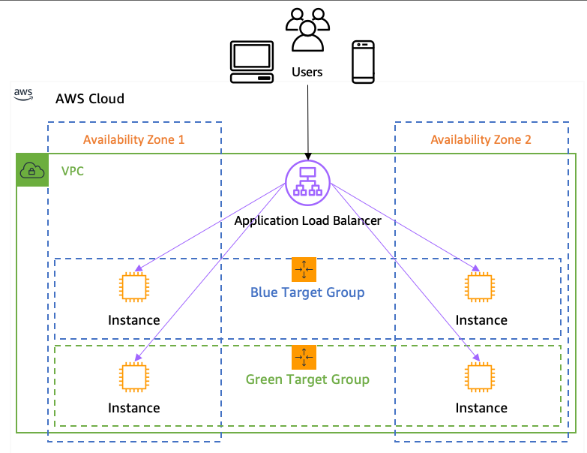 |
- 가중치 8과 2가 지정된 두 개의 대상 그룹을 포함하는 규칙을 정의하면, 로드 밸런스가 트래픽의 80%를 첫 번째 대상 그룹으로, 20%를 두 번째 대상 그룹으로 라우팅 - 새 앱 버전에 대한 블루-그린 배포(Blue-Green Deployment) 시에도 활용할 수 있다. - Blue가 구버전, Green이 신버전으로 각각 가중치를 80%, 20%를 준다. - Green 사용자의 반응이 좋으면 Green으로 가중치를 100%으로 수정하고, - 반응이 좋지 않으면 다시 가중치를 Blue에 100% 둘 수 있다. |
② Network Load Balancer
- L4 즉, TCP와 UDP를 사용하는 요청에 대한 부하분산 목적의 로드밸런서
- 매우 짧은 대기 시간을 유지하면서 대규모 트래픽 처리에 적합
- 소스 IP/Port, 대상 IP/Port 정보를 활용한 로드밸런싱
- IPv4만 지원, 고정 IP 혹은 탄력적 IP 설정 지원
③ Gateway Load Balancer
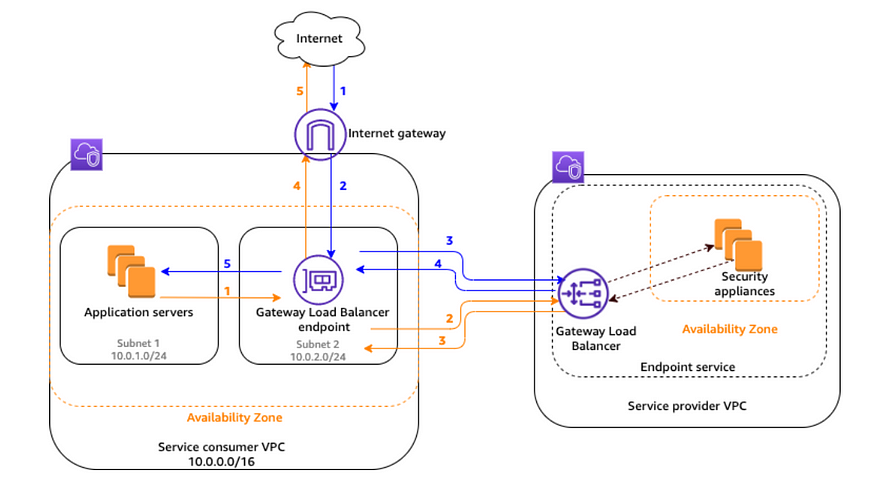
- 방화벽(트래픽 분석 및 차단), 패킷 검사, 침입 탐지 시스템 등과 같은 가상 보안 어플라이선스에 트래픽을 전달하고 관리하기 위한 서비스
- 가상 어플라이언스는 게이트웨이 로드밸런서의 대상 그룹으로 등록되며 수요에 따라 가상 어플라이언스를 자동 확장하면서 트래픽을 분산한다.
** 리전간 부하분산
- ELB는 단일 리전 내 부하분산을 위한 서비스인데, 전역적인 리전간 부하분산은 어떻게 구현해야 할까?
3. Route53
- 높은 가용성과 확장성이 뛰어난 클라우드 DNS(Domain Name System) 서비스
- 전 세계 DNS 서버의 글로벌 애니캐스트 네트워크를 사용하여 최적의 위치로 사용자 요청을 자동으로 라우팅한다.
- 전역적으로 유연한 고가용성 아키텍처를 지원하고 다양한 라우팅 유형을 통해 트래픽을 관리할 수 있다.
- 사용자 요청을 여러 리전에 있는 EC2 인스턴스, ELB, S3 버킷 등에 효과적으로 연결한다.

(1) 라우팅 정책
| 정책 | 내용 |
| 단순 라우팅 (Simple Routing) |
- 하나의 리소스(ex.특정 웹서버)로 트래픽을 라우팅하고자 할 경우 활용 |
| 가중치 기반 라우팅 (Weighted Routing) |
- 할당된 다른 가중치 기반으로 트래픽을 분할 - 블루-그린 배포 등에 활용할 수 있음 |
| 지리 위치 라우팅 (Geolocation Routing) |
- DNS 쿼리가 발생한 지리적 위치 기반으로 지원할 리소스를 선택 - ex. 콘텐츠를 현지화하고 웹 사이트를 사용자의 언어로 표시 |
| 지연 시간 기반 라우팅 (Latency based Routing) |
- 물리적 거리가 아닌 지연시간 기반으로 라우팅 - 여러 리전의 실제 성능 측정치를 기준으로 가장 빠른 환경을 제공하는 리전으로 라우팅 - 독일에서 발생하는 트래픽이 지리적으로 따지면 서울보다 영국이지만, 지연 기반 시간이 서울이 더 짧으면 서울로 라우팅할 수 있다. |
| 장애 조치 라우팅 (Fail-over Routing) |
- 주로 재해 복구에 사용되는 'Active-Standby' 장애 조치 개념 - 웹 사이트의 가동 중단을 탐지하고 사용자를 애플리케이션이 제대로 작동하는 대체 위치로 리디렉션 |
| 지리 근접 라우팅 (Geoproximity Routing) |
- 리소스 기준으로 트래픽을 처리할 지리적 크기(Bias)를 지정 - 지정된 Bias 내에서 발생한 사용자 요청을 처리 (Bias는 변경 가능) - 만약 A에 대한 Bias를 10%로 줄이면, 다른 영역에 대한 Bias를 10% 늘려야 함 |
(2) DR 체계 구현

* 왼쪽으로 갈 수록 느린 복구 속도, 낮은 비용 / 오른쪽으로 갈 수록 빠른 복구 속도, 높은 비용

① Pilot Light
- 클라우드에 온프레미스와 동일한 환경을 구성해놓지만 평상 시 중지 상태로 유지
- DB의 데이터는 자동 복제가 되도록 구성
- 장애 발생시 리소스를 실행시키고 요청 트래픽을 클라우드로 전환하여 서비스
- 상대적으로 저렴한 DR 체계이지만, 대응하는데 시간은 오래 걸린다.
② Warm Standby
- 온프레미스의 리소스보다 작은 최소 용량의 리소스만 클라우드상에서 실행되도록 구성
- 장애 발생 시 오토 스케일링 그룹을 통해 온프레미스 리소스 개수만큼 클라우드 리소스를 즉시 자동 확장하고 요청 트래픽을 클라우드로 전환하여 서비스
- Pilot Light 보다 더 빠른 대응이 가능하나 비용은 더 발생한다.
③ Multi-site active/active
- 온프레미스 시스템과 동일한 수준의 서비스 체계를 클라우드 상에 구축하고 평상 시 요청 트래픽을 50%:50%으로 서비스
- 장애 발생 시 가중치 기반 라우팅을 통해 클라우드로 요청 트래픽이 100% 전달되도록 구성
- 즉각적이고 안정적인 장애조치가 가능하지만 비용이 가장 많이 발생한다.
'클라우드 서비스' 카테고리의 다른 글
| [클라우드 서비스] Serverless _ 20241205 (2) | 2024.12.09 |
|---|---|
| [클라우드 서비스] Loosely Coupled Arch. _ 20241205 (0) | 2024.12.08 |
| [클라우드 서비스] Microservices_20241205 (3) | 2024.12.08 |
| [클라우드 서비스] Database Service _ 20241204 (5) | 2024.12.06 |
| [클라우드 서비스] Storage Service _ 20241204 (5) | 2024.12.06 |



