1. 시각화
(1) 평균 비교 : bar plot
sns.barplot(x="Survived", y="Age", data=titanic)
plt.grid()
plt.show()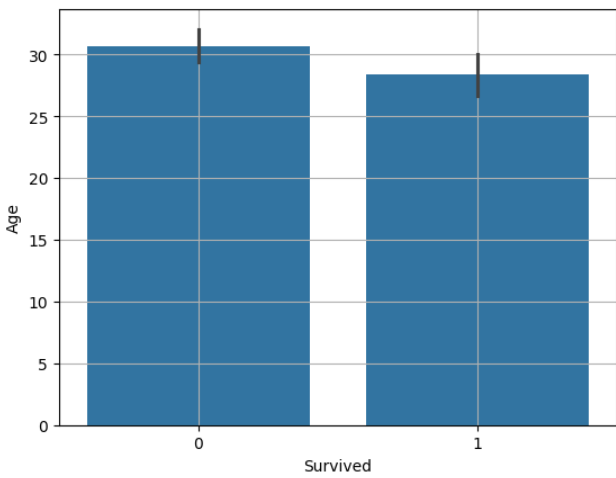 |
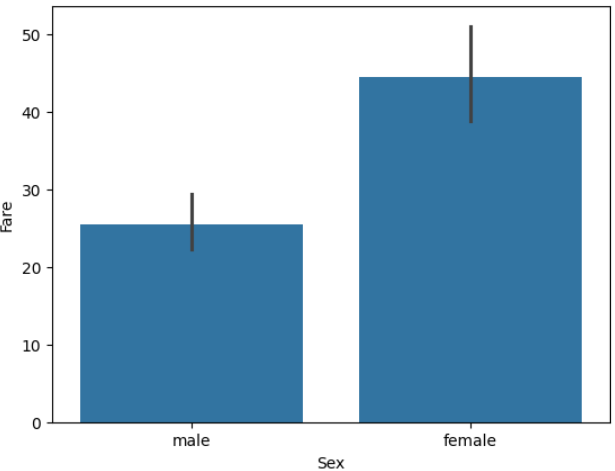 |
| sns.barplot(x="Survived", y="Age", data=titanic) | sns.barplot(x='Sex', y='Fare', data=titanic) |
2. 수치화
(1) t-test : spst.ttest_ind(df1, df2)
- t 통계량 : 두 평균의 차이 (정확하게는 두 평균의 차이를 표준오차로 나눈 값)
- 보통 t 값이 절댓값 2보다 크면 차이가 있다고 본다.
더보기
가설
Age : 생존여부 별로 나이에 차이가 있을 것이다.
# NaN 값 확인
titanic.insull().sum()
# NaN 행 삭제
temp = titanic.loc[titanic['Age'].notnull()]
# 두그룹으로 데이터 저장
died = temp.loc[titanic['Survived']==0, 'Age']
survived = temp.loc[titanic['Survived']==1, 'Age']
spst.ttest_ind(died, survived)
결과 : statistic=2.0666869... / pvalue=0.03912465..
통계량이 절대값 2보다 크고, pvalue가 0.05보다 크므로 상관관계가 있고 유의미하다고 볼 수 있다.
(2) anova (ANalysis Of VAriance : 분산 분석) : spst.f_oneway(df1, df2, df3)
# 1) 분산 분석을 위한 데이터 만들기
# NaN 행 제외
temp = titanic.loc[titanic['Age'].notnull()]
# 그룹별 저장
P_1 = temp.loc[temp.Pclass == 1, 'Age'] # temp['Pclass']
P_2 = temp.loc[temp.Pclass == 2, 'Age']
P_3 = temp.loc[temp.Pclass == 3, 'Age']
# 2) 결과
statistic=57.443484340676214, pvalue=7.487984171959904e-24
통계량이 크고, pvalue가 0.05 이하이므로 유의미하다.
'파이썬 > 데이터 분석' 카테고리의 다른 글
| [240930] 데이터 분석 #7 이변량 - 숫자 vs 범주 (5) | 2024.10.01 |
|---|---|
| [240930] 데이터 분석 #6 이변량 - 범주 vs 범주 (0) | 2024.10.01 |
| [240927] 데이터 분석 #4 평균에 대하여 (0) | 2024.09.27 |
| [240926] 데이터 분석 #3 이변량 - 숫자 vs 숫자 (0) | 2024.09.27 |
| [240926] 데이터 분석 #2 개별 변수 분석 - 범주형 변수 (2) | 2024.09.27 |



